The CBF seeks to remove the informatics bottleneck in the omics pipeline by offering solutions ranging from large scale analysis, such as full systems biology investigations, to smaller scale and bespoke services. We also offer training in most common computational biology aspects.
Data science
A large proportion of activity at the CBF is devoted to large data analyses, including multi-omics integration in order to model biological systems. You can consult some of our work in biomarker discovery, drug repositioning, networks analyses and systems toxicology.
The diagram below summarises the conceptual framework we use to describe our scientific approach. Our approach integrates data-driven computational approaches for the discovery of biological mechanisms and biomarkers (A and B) with mechanistic modelling (C) with the ultimate aim of developing software platforms to support decision making from basic research to clinical applications.
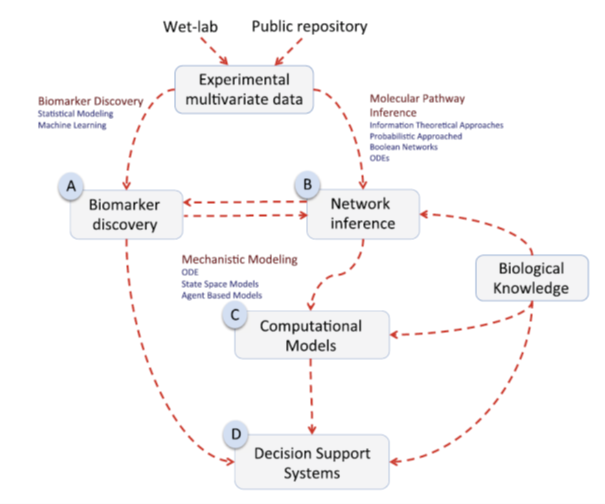
Conceptual framework describing the scientific approach of the CBF.
We integrate knowledge from different sources (wet-lab and public repositories) to build complex multilevel datasets that can be exploited with different interconnected aims. Data sources can include multi-omics data (genomics, transcriptomics, proteomics, metabolomics, etc), imaging (such as MRI) and other types of biological data.
These may then be used to identify predictive biomarkers for a given outcome (cancer resistance, toxic level, etc.) or to inform development of relevant networks that may infer such outcomes. Both of these can be built using a combination of statistical methods including machine learning or differential equations and further refined with extra data acquired for validation purposes.
These networks can be embedded in computational models that are able to explore underlying molecular mechanisms that, in parallel with biological knowledge of the particular area of study, can be refined and used to create knowledge-based decision support systems. These offer potential for in silico experimentation, considerably reducing costs of research and robustness of decisions.
Read some of our data science case studies
Software and database solutions
The CBF has software engineers ready to help you get the most out of your research. Our engineers are fluent in multiple programming languages and up-to-date with cutting edge algorithmic and graphical techniques. With years of industry experience, our engineers are motivated to help you get the most from your experiments and to ensure your findings are accessible to the world.
Read about some examples of software solutions we have created
Protein bioinformatics
Professor Dan Rigden is a specialist in protein sequence and structural bioinformatics. His expertise brings a range of services across protein sequence and structure bioinformatics to the CBF which are available to help you predict, understand and redesign protein activities. These services cover protein modelling of all kinds and the use of such models for applications, from biomedical (e.g. structure-based SNP interpretation), to biotechnological (e.g. genome mining), protein design.
Read more about our protein bioninformatics work
Courses
We offer continuous professional development courses in various aspects of computational biology. If you want to learn how to analyse your data or how to start programming have a look at details of our courses.
Back to: Computational Biology Facility